Rust - Le stringhe
Abbiamo introdotto il concetto di barrowing
nel paragrafo precedente. In questo capitolo introduciano la nozione di
ownership altro pilastro di questo
linguaggio. Ne parliamo grazie alle stringhe o meglio
è un buffer di byte UTF‑8 validi, posseduto e mutabile , differenti da quelle immutabili
e"prestate" incontrate nello scorso paragrafo.
La keyword che le identifica è
String e rappresenta qualcosa di un po'
più complesso rispetto alle string slice viste in precedenza. Dal punto di
vista della "velocità", del peso computazionale, esse sono forse un po' più lente nell'uso rispetto
a &str ma sono anche modificabili "in place" ovvero senza necessità che in
caso di modifiche se ne debba creare una nuova, possono quindi crescere di
dimensione, diminuire ecc.. il che le rende strumenti estremamente
duttili. D'altro canto, è anche possibile che modifiche apportate
possano obbligare ad una completa riallocazione degli elementi (perchè ad
esempio aggiungendo nuovi caratteri lo spazio contiguo in memoria non è
sufficiente in quella locazione e quindi la stringa necessita di essere
spostata in una nuova area) ed ecco
un motivo per cui potrebbero essere più pesanti dal punto di vista
prestazionale.
Una caratteristica fondamentale delle stringhe è che
esse coinvolgono sia lo stack che lo heap. Infatti
suoi elementi costitutivi sono allocati nello heap, cosa che è intuibile
considerando la natura dinamica di questa struttura dati che ben si
coniuga con quella zona di memoria, ma viene
coinvolto anche lo stack nel quale è allocata la struttura di base, per cui, a questo punto, direi che è bene
chiarire la situazione che si presenta nel momento in cui avremo creato
la nostra stringa:
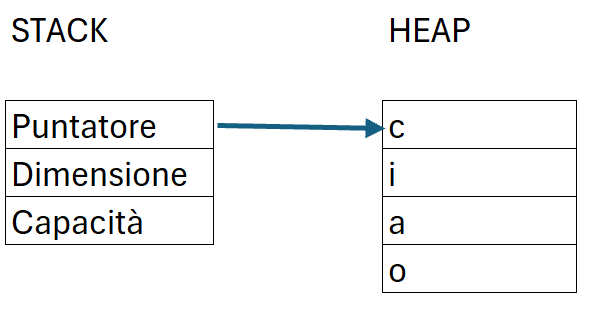
- nello stack abbiamo:
un puntatore - diretto all'indirizzo dello heap in cui si trovano gli elementi della stringa, o meglio, diretto al primo elemento della sequenza
una dimensione - quella attuale della stringa
una capacità - lo spazio allocato per la stringa indipendentemente dalle sue dimensioni attuali. La capacità è importante perchè può limitare la necessità di riallocazioni che potrebbero influire sulle prestazioni. - nello heap troviamo invece i dati della stringa
Vediamo ora come creare una stringa, per uniformità e coerenza le
presentiamo tutte come mutabili:
1) attraverso
new( )let mut s1 = String::new();
abbiamo creato una stringa vuota alla quale si potranno
aggiungere altri elementi se ovviamente si è messa, come in questo caso, la clausola
mut
2)
partendo da una string slice con il metodo to_string( ) oppure
to_owned( )
let mut s1 = "ciao".to_string();
let mut s1 = "ciao".to_owned();
questi due metodi sono in pratica equivalenti ma il secondo è
operativamente più leggero e in linea di massima quest'ultimo è quello da
preferire nell'uso pratico anche per ragioni puramente idiomatiche: infatti
più che una conversione c'è una presa di possesso della sequenza di
caratteri. Se invece dobbiamo convertire qualcosa che non è una stringa, ad
esempio un numero, allora si deve usare to_string( ).
3) usando from(
)let mut s1 = String::from("ciao");
4) usando into( )
let mut my_str = "Questo è un test";
let mut s1: String = my_str.into();
5) usando la macro format!
let mut s1 = format!("{} {}", "hello",
"world");
6) partendo da un vettore di byte (dobbiamo ancora parlare
dei vettori e degli array) tenendo presente che i valori nell'array devono
essere UTF-8 validi per convenire alla definizione iniziale:let vec
= vec![104, 101, 108, 108, 111]; // 'hello' in ASCII
let mut s1 =
String::from_utf8(vec).unwrap();
7) partendo da una sequenza di
caratteri:use std::iter::FromIterator;
fn main() {
let chars:
Vec<char>= vec!['a', 'b', 'c'];
let mut s1 = String::from_iter(chars);
}
Esistono altre strade, ma per ora queste possono bastare. Non è
necessario che tutti questi sistemi siano chiari adesso, potrete tornarci
sopra in seguito quando avremo affrontato altri argomenti, abbiamo già
accennato ad array e vettori, ci aggiungo anche gli iteratori.
Di
passaggio risolviamo subito un problema che molti si pongono ovvero come
passare dalle slice che abbiamo visto nel capitolo precedente a String e
viceversa; il problema è di facile soluzione:
let s1: String = "abc".to_owned();
let s2: &str = &s1[..];
la prima scrittura ci porta da slice a stringa, come al punto 2) precedente, la seconda tramite creazione di un puntatore costruisce una string slice.
Quando definiamo una stringa in uno dei modi visti in precedenza, il contenuto è in suo pieno possesso per questo motivo si parla di ownership. Le basi dell'ownership sono tre:
- ogni valore ha un solo owner (proprietario)
- può esservi quindi un solo proprietario per volta
- quando il proprietario esce dallo scope il valore nello heap è eliminato
L'ultimo punto in particolare è importante per capire come Rust provveda
automaticamente a ripulire in maniera sicura lo heap da elementi non più
necessari. La pulizia è sicura sulla base dei primi due punti che
garantiscono che non ci sia il rischio di imbattersi nei famosi e temuti
dangling pointers.
Il seguente codice, che si basa su una string slice,
compila e stampa due volte la stringa "abc" a video:
let s1: &str = "abc";
let s2 = s1;
println!("{}", s1);
println!("{}", s2);
questo secondo codice invece non compila:
let s1 = String::from("abc");
let s2 = s1;
println!("{}", s1);
println!("{}", s2);
e l'errore che ci presenta è molto interessante:
error[E0382]: borrow of moved value: `s1`
--> r141.rs:4:20
|
2 | let s1 = String::from("abc");
|
-- move occurs because `s1` has type `String`, which does not implement the
`Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
println!("{}", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which
comes from the expansion of the macro `println` (in Nightly builds, run with
-Z macro-backtrace for more info)
help: consider cloning the value if the
performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
Error: aborting due to 1 previous error
For more
information about this error, try `rustc --explain E0382`.
in particolare le righe evidenziate in rosso sono estremamente
indicative: La macro di stampa cerca di prendere in prestito
(borrow) la stringa s1 ma il valore di questa è stato mosso,
ovvero ha cambiato padrone e noi sappiamo che, a seguito della seconda riga
del codice, che questo valore è stato assegnato alla variabile s2 che ora ne
è il proprietario, l'unico proprietario, come da regole che
delimitano l'ownership.
La seconda riga evidenziata ci spiega che le stringhe non implementano il
trait copy quindi l'unico modo per
completare l'assegnazione è il passaggio di proprietà verso s2. Ne consegue
partanto che s1 è uscita dallo stack (non ci sarà il temuto double free
error) ma la stringa nello heap non subirà un dropping perchè s2 punta
ancora ad essa. E siccome il compilatore vuole andare fino in fondo e si
traveste un po' da insegnante del linguaggio, ci invita ad usare il metodo
clone che lavora
diversamente da copy come vedremo. Tenete
presente fin da subito che clone è
piuttosto pesante come operazione e il compilatore vi dice infatti "if the
performance cost is acceptable". Il primo esempio invece che si basava sulle
string slice funziona senza problemi perchè il borrowing permette
più puntatori ad una stringa letterale come abbiamo visto nel
precedente paragrafo.
Avremo modo di vedere il concetto di ownership in
azione in vari ambiti, dalla concorrenza a struttura dati interessanti come
gli enumerativi o i vettori.
Tenete presente però che è bene fare un discorso profondo su barrowing e ownership così da avere le idee chiare su questo fondamentale argomento. Lo faremo nel prossimo paragrafo anche con esempi che potranno non essere chiari all'inizio, quindi vi invito a tornarci sopra perchè, ripeto, è assolutamente essenziale comprendere questi argomenti che costituiscono il modello che ha portato al successo di questo linguaggio.
E' il momento di presentare come potrete lavorare con le String.
Il materiale è tanto ne presento una parte che ritengo utile ed interessante.
Da un punto di vista tecnico una stringa è array di u8 (vec<u8>
non preoccupatevi per la definizione per adesso) e tutti i suoi elementi devono
essere UTF8 validi. Anche per loro esiste una indicizzazione che inizia
da 0 e prosegue progressivamente di una unità per ogni elemento.
Gli indici devono essere di tipo usize come nel caso delle string slice,
particolare da non dimenticare mai.
La lunghezza di una stringa è rilevabile tramite il consueto metodo len( ) tenendo presente che, anche in questo caso, viene espressa la lunghezza, in byte e quindi non si tratta esattamente del conteggio degli elementi:
let s1: String = "abè".to_owned();
let s2: String =
"abc".to_owned();
println!("{}", s1.len());
println!("{}", s2.len());
qui s1 avrà lunghezza 4 ed s2 lunghezza 3 per i motivi già specificati nel paragrafo
relativo alle string slice. Ricordiamoci sempre che parliamo di elementi
UTF8 non di semplici caratteri ASCII.
Se vogliamo il numero di elementi
possiamo, come per le string slice ricorrere a
chars().count(), più pesante:println!("{}", s1.chars().count());
Altro problema, aggiungere, o meglio appendere elementi in una stringa, che ovviamente deve essere mutabile, abbiamo il metodo push(carattere), vediamo un esempio che parte da una stringa vuota:
Esempio 10.1
fn main(){
let mut s1 = String::new();
s1.push('a');
s1.push('b');
s1.push('2');
println!("{}", s1);
}
che costruisce la stringa "ab2".
il metodo clear() cancella
tutti gli elementilet
mut s1 = "ciao".to_string();
s1.clear();
mentre remove(indice) elimina
l'elemento alla posizione indicata dall'indice o meglio rimuove il carattere
UTF8 che inizia al byte "indice":let mut s1 =
"ciao".to_string();
s1.remove(3);
println!("{}", s1);
questo spezzone ci
propone in output la stringa "cia" privata quindi dell'elemento alla
posizione 3, la lettera 'o'.
Al contrario insert() inserisce un
carattere alla posizione indicata (più avanti vedremo un altro sistema):
let mut s1 = "ciao".to_string();
s1.insert(3, 'r');
println!("{}",
s1);
che ci restituisce la parola "ciaro" avendo inserito la lettera
'r' alla posizione con indice 3.
Forse ancora più utile è insert_str(indice,
string slice) tramite il quale possiamo inserire una string slice alla
posizione che indichiamo con l'indice.let mut s1 =
"ciao".to_string();
s1.insert_str(3, "sss");
println!("{}", s1);
e il nostro "ciao" diventa uno strambo "ciassso".
Possiamo
invece sostituire uno o più caratteri nella stringa e un modo semplice per
fare questa operazione è ricorrere a
replace_range(range, stringa).
Esempio 10.2
fn main(){
let mut s1 = "aaaaa".to_owned();
println!("{}", s1);
s1.replace_range(1..3, "www");
println!("{}", s1);
s1.replace_range(0..1, "z");
println!("{}", s1);
s1.replace_range(0..0, "k");
println!("{}", s1);
}
con output:
| aaaaa awwwaa zwwwaa kzwwwaa |
- la riga 5 sostituisce gli elementi con indice 1 e 2 (il range non è
inclusivo) con la stringa "www"
- la riga 7 sostituisce l'elemento
all'indce 0 con la stringa (non carattere) "z"
- la riga 9 inserisce la
stringa "k" all'indice zero (fa lo stesso lavoro di insert()).
Tutte le modifiche effettuate in questi esempi modificano la stringa senza crearne un'altra. L'ownership esercitata sul contenuto significa proprio questo. Ragionando su questo argomento, è inevitabile constatare che possono esservi problemi di performance quando si operano molte modifiche che possono costringere a riallocazioni dell'intera sequenza. Un modo per calmierare le cose può essere quello che fa uso del metodo with_capacity(n). Tale metodo predispone lo spazio indicato per accogliere una stringa ed è quindi indicato qualora si sappia le dimensioni di quello che sarà accolto o ci si voglia comunque cautelare entro certi margini.
let mut s1 = String::with_capacity(50);
Qui s1 ha lunghezza 0 ma
per essa è già predisposta una capacità di 50 elementi. Qualora dovessimo
aggiungerne non sarà necessario quindi allocare nuovo spazio, tutto a
vantaggio delle prestazioni. Rovescio della medaglia: se predisponete spazio
senza criterio e poi non serve sprecate memoria.
L'accesso al singolo elemento è il medesimo visto per le string slice:
let s1 = "abcd".to_owned();
println!("{:?}",
s1.chars().nth(2).unwrap());
è interessante notare che il seguente
codice funziona:fn main() {
let s1 = "abcd".to_owned();
let
x = 2;
println!("{:?}", s1.chars().nth(x).unwrap());
}
mentre
quest'altro origina un errore:fn main() {
let s1 =
"abcd".to_owned();
let x: i32 = 2;
println!("{:?}",
s1.chars().nth(x).unwrap());
}
questo perchè nel secondo caso
Rust non può convertire in usize un elemento che abbiamo imposto essere un i32.
Selezionare un indice fuori range, in questa fase almeno,
dà origine ad
un crash (o meglio un panic) del programma. Questo vale anche per le string slice, naturalmente.
Dico in questa fase perchè più avanti impareremo a gestire anche queste
sictuazioni.
La concatenazione delle stringhe è ottenibile in vari
modi:
il primo è il classico concat! che
si applica su string slicelet s3 = concat!("ciao", "ciao", "ciao");
oppure
concat(), come visto con le
string slicelet s1 = "ciao".to_string();
let s2 =
"ciao".to_string();
let s3 = [s1, s2].concat();
anche push_str(stringa) permette di unire una stringa con una string slice
let mut s1 = "ciao".to_string();
s1.push_str("ddd");
oppure
operando sulle stringhe:let mut s1 = "aaa".to_string(); //
s2 usata per riferimento
let s2 =
"bbb".to_string();
s1.push_str(&s2);
e
poi abbiamo già visto, ovviamente format! che lavora direttamente su
stringhelet s1 = "aaa".to_string();
let s2 = "bbb".to_string();
let s3 = format!("{}{}", s1, s2);
Si può anche usare l'operatore +:
let s1 = "aaa".to_string(); // s2 è usata per riferimento
let s2 = "bbb".to_string();
let s3 =
s1 + &s2;
è interessante notare appunto
che con il + il secondo termine deve essere usato per riferimento. Questo
perchè usa l'implementazione interna di Add che è definita, in parte, come
segue:fn add(mut self, other: &str) -> String
Altra considerazione importante relativa a quest'ultimo esempio, è che il
+
"consuma" il termine s1 che viene mosso e a quel punto ad
esempio il tentativo di stamparlo darebbe errore. Su questo occorre fare un
po' di attenzione.
Sinceramente trovo più lineare , leggibile e sicuro
usare format! rispetto al
+ in particolare se dovete concatenare più
stringhe che aggiunge anche una conversione implicita da &String a &str
(parliamo del secondo parametro ovviamente)
Per trovare la prima occorrenza di un carattere in una stringa potreste usare il metodo find(carattere). Questo restituisce un tipo Option, che vedremo nella apposita sezione per cui potreste, di primo acchito avere qualche sorpresa. Per ora prendete l'esempio così come viene:
Esempio 10.3
fn main(){
let s1 = "aaa".to_string();
println!("{:?}", s1.find('a'));
println!("{:?}", s1.find('k'));
}
che restituisce:
| Some(0) None |
Come detto questo sarà più chiaro quando vedremo il tipo Option. Evidentemente 0 è l'indice della prima occorrenza di 'a' mentre None si riferisce al fatto che 'k' non è presente nella stringa "aaa". Un altro metodo fa uso dell'iteratore chars():
println!("{}", s1.chars().position(|x| x == 'a').unwrap());
Per copiare una stringa in un'altra seguiamo il suggerimento che ci ha dato in precedenza il compilatore quando avevamo cercato di usare il segno = per effettuare l'operazione. Facciamo uso quindi di clone():
Esempio 10.4
fn main(){
let mut s1 = "aaa".to_string();
let s2 = s1.clone();
println!("{}", s1);
println!("{}", s2);
s1 = "yyy".to_string();
println!("{}", s1);
println!("{}", s2);
}
da cui otteniamo:
| aaa aaa yyy aaa |
le due stringhe sono indipendenti e le variazioni su s1 non influiscono su s2.
Chiudiamo con una annotazione più leggera: anche con le nostre String, è
possibile scrivere l'output su più righe inserendo un " a
capo" che può essere eventualmente aggirato, proprio come abbiamo visto nel
capitolo precedente. let s1 = "ciao
Mondo".to_owned();
let s2 = "ciao\
Mondo".to_owned();
Questa è solo una panoramica superficiale di
quanto disponibile per le stringhe. Il sito ufficiale, nella pagina
dedicata, riporta ovviamente tutto e, come per le string slice, vi consiglio
di dare una lettura a quanto vi troverete.
Torniamo per un attimo,
per concludere, ad una questione che a volte sorge riguarda la convenienza
dell'uso delle slice string o delle stringhe. In generale le prime si fanno
preferire in quanto più leggere e performanti, specialmente in progetti
pesanti. Se avete bisogno della possibilità di modificare una sequenza di
caratteri le stringhe sono il tipo adatto, in particolare se ne potrete
definire in anticipo la capacità, così come quando non sapete quanto sarà
la durata, nell'ambito del programma, della vostra sequenza.
Rust ci
propone anche la possibilità di creare delle cosiddette byte string literal
(uno slice di byte, in sostanza) che si caratterizzano con il prefisso
'b'
davanti alla stringa stessa. Esempio:let s = b"ciao";
in
pratica, come definizione generica e forse quella più nota, mentre una
stringa normale ("ciao") è una sequenza di caratteri Unicode, una byte
string è una sequenza di numeri interi a 8 bit che rappresentano i codici
ASCII di quei caratteri. Affinchè la byte string sia valida i valori
numerici devono coincidere solo con corrispondenti caratteri ASCII. Quindi
solo se tutti i byte che contiene sono valori compresi tra 0 e 255.
Diversamente vengono rifiutati. Si usano prevalentemente nella
programmazione di sistema o in alcune forme di crittografia.
Infine
segnalo, ma ne parleremo altrove, anche le
&Cstr
ed è il tipo
che rappresenta una C string immutabile, cioè una stringa in stile C:
--- terminata da byte 0 (\0)
--- contenente byte arbitrari, non
necessariamente UTF‑8
--- vista come &[u8] fino al terminatore
ovviamente usata per interoperabilità con il linguaggio C. Anche
questo argomento, per ora, va al di là dei nostri scopi.
Per concludere inserisco una tabella comparativa tra string slice e String:
| Caratteristica | String |
&str |
|---|---|---|
| Allocazione | Heap | Nessuna (slice su dati esistenti) |
| Mutabilità | Mutabile (se mut) |
Sempre immutabile |
| Ownership | Possiede i dati | Non possiede, è un riferimento |
| Lunghezza | In byte | In byte |
| UTF‑8 | Sempre valida | Sempre valida |
Copy |
No | Sì |
Clone |
Sì (copia i byte) | Triviale (copia il riferimento) |